主旨
飲食店でのソーシャルディスタンス(死語になりつつあるが)確保や人件費の節約の観点から ロボットを用いて配膳を自動で行う需要がある。今回のプロジェクトでは可視光カメラのみからの位置情報推定と、ジェスチャーからのセマンティクス抽出を用いて手を上げた人の所にロボットを向かわせることに取り組んだ。
手法
システム構成
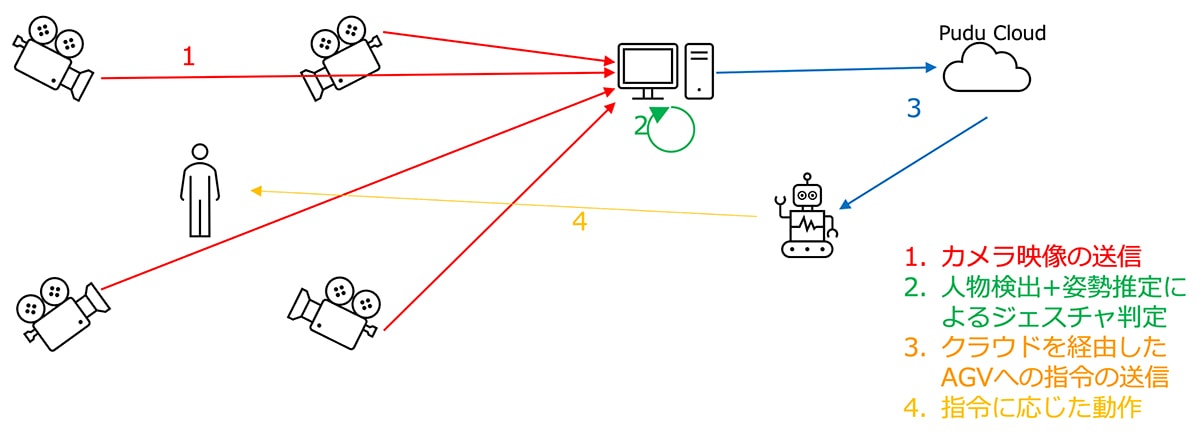
カメラ複数台(ここでは4台)を用いて画像からジェスチャ(ここでは挙手)を検出する。検出された人を三次元空間で再構成し位置を求めて、その座標にロボットを送る指令を出す。
- 画像から姿勢を推定する手法:simpleHRNet
- 複数のカメラで得られた姿勢から人の位置・姿勢を三次元的に再構成する手法:EasyMocap
- 用いたロボット:KettyBot
結果
7m四方程度の空間で実験を行い、ジェスチャを用いてロボットを動かした。ロボットを挙手している人に向かわせることに成功した。
考察
実験の成功から三次元空間での姿勢の認識と位置の推定、ロボットへの指令の送信が成功していることがわかる。
展望
- 実際の飲食店での運用を考慮してより広い空間での実験
姿勢の推定や三次元的な位置の推定が困難になる可能性がある - Wi-Fiが飛び交う空間での混線の影響による通信障害の対策
カメラ映像やロボットへの指令が遅れない可能性がある - 複数のロボットの運用
複数人が手を挙げた際にどのロボットを向かわせるか、のようなスケジューリングを考える必要がある