背景
- 企業の経営戦略活動の差はわかりにくい、定量的・視覚的な比較がしづらい
- 新聞の記事のデータはタグレベルでしか管理がされていない
- 新聞には膨大な量のデータがあるにも関わらず有効活用されていない
目的
機械学習の一分野である自然言語処理を利用して、新聞のデータを自動でカテゴリ分けし、企業の経営戦略活動の分析を可能にする。
※ このプロジェクトでは、新聞記事のテキストデータから分散表現を作り、経済活動・経営戦略活動的なトピックを教師あり学習で分類しました。最新の言語系AIの性能には劣りますが、2017年〜2018年に行われた物であり、当時としては画期的でした。
参考:自然言語処理
人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野である。
(wikipediaより)
単語類似度
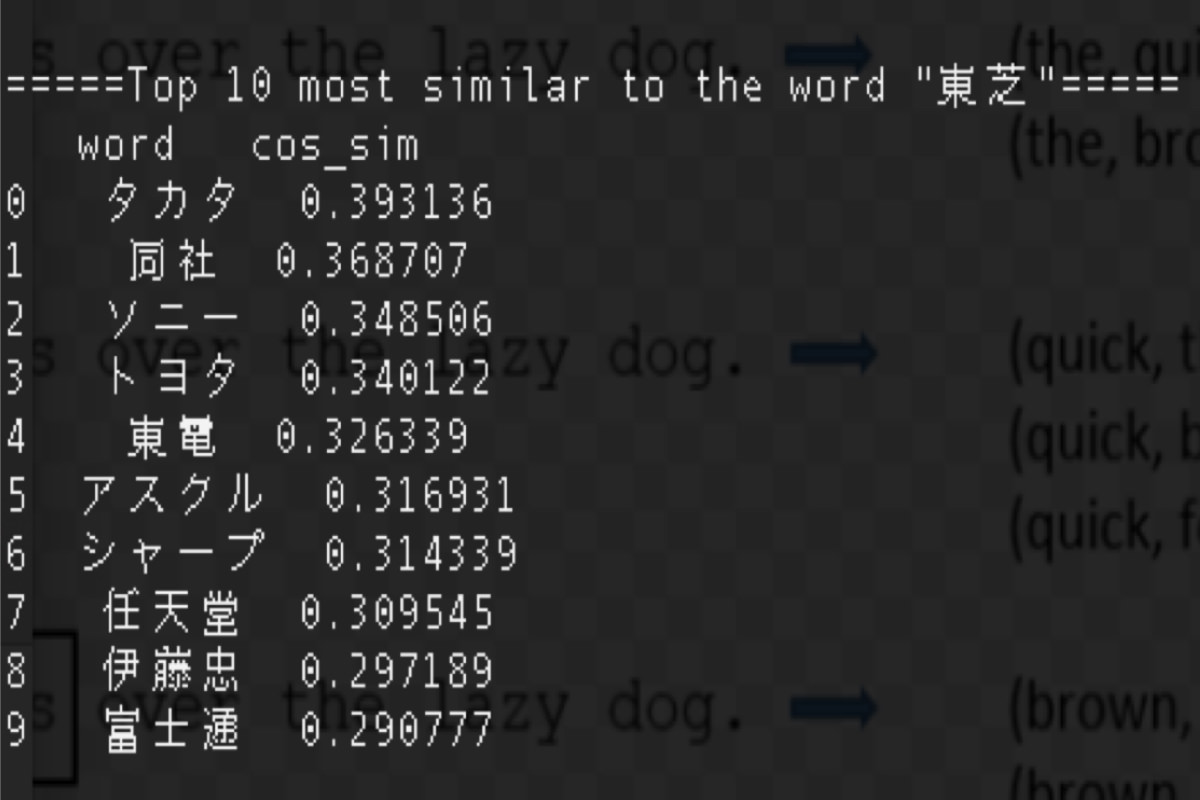
「東芝」という単語の類似度を持つ単語の例
「タカタ」や「ソニー」、「トヨタ」などの会社名を類似の単語として理解している。
センテンス類似度
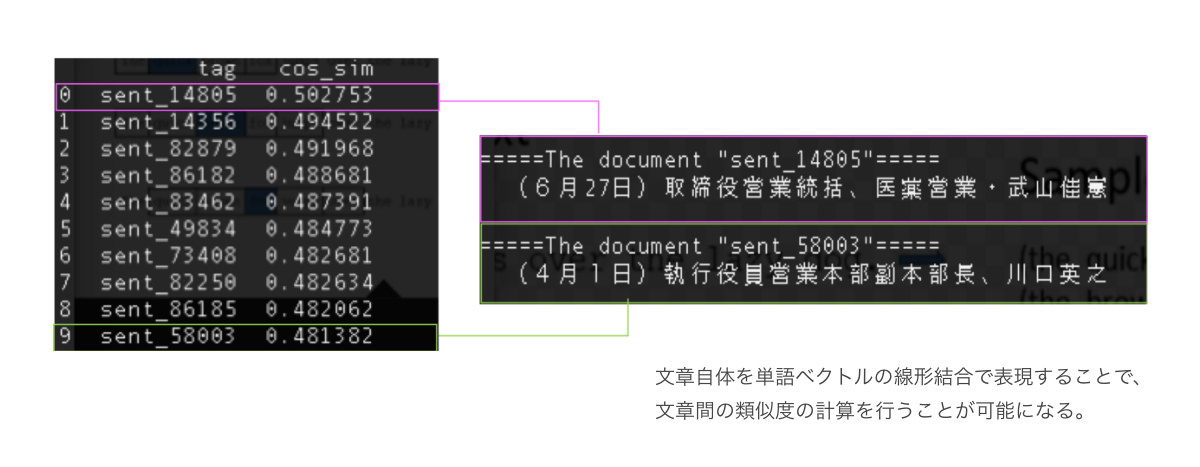
文章自体を単語ベクトルの線形結合で表現することで、文章間の類似度の計算を行うことが可能になる。
類似度判定の具体例
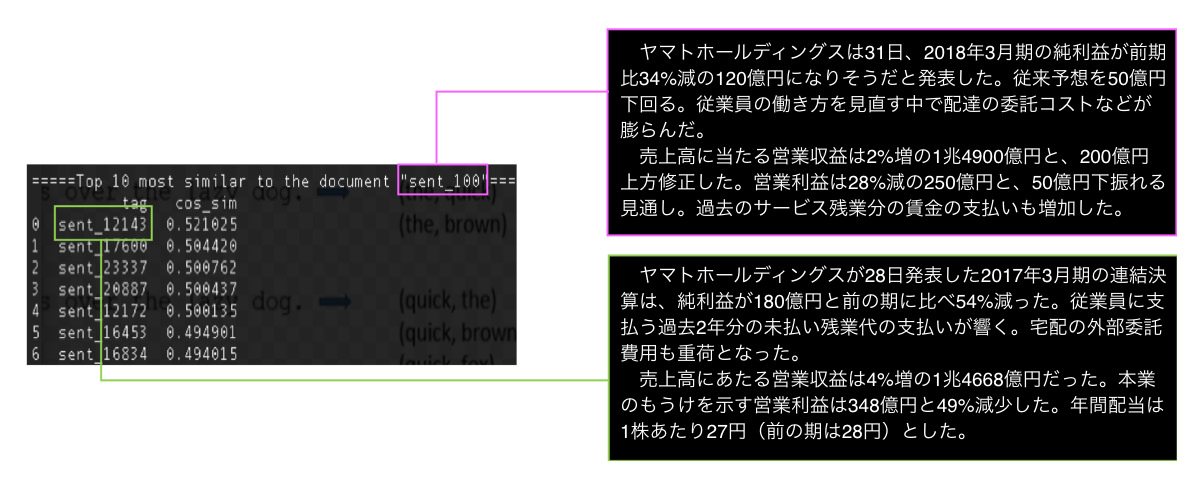
分析結果:富士フィルムとリコーの比較(実際のアプリケーションより引用)
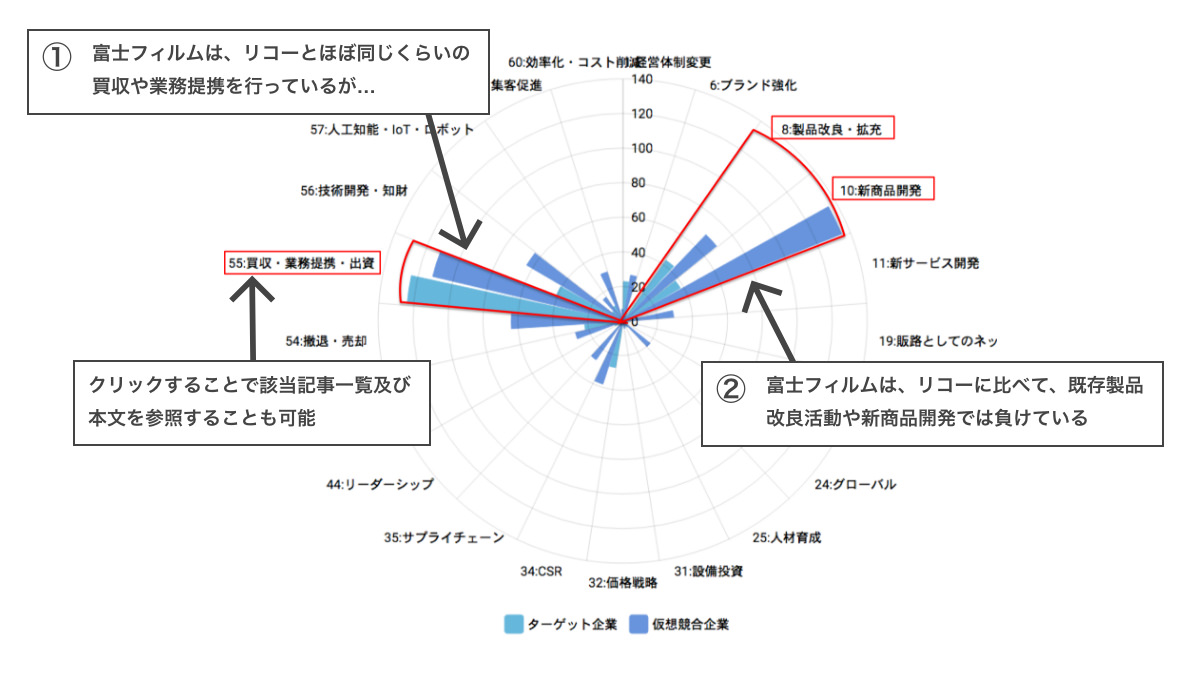
想定ユースケース
基本:PRコンサル/経営コンサルにおける初期のエビデンス調査、SWOT分析
- 競合他社との相対化
- 世間からみた企業イメージの定量化
- 他業界でも似ている企業の発見
- (発展)日経テレコンなどのソースを利用したエビデンス発見